Cosine Similarity Part 1: The Basics
The business use case for cosine similarity involves comparing customer profiles, product profiles or text documents. The algorithmic question is whether two customer profiles are similar or not. Cosine similarity is perhaps the simplest way to determine this.
If one can compare whether any two objects are similar, one can use the similarity as a building block to achieve more complex tasks, such as:
- search: find the most similar document to a given one
- classification: is some customer likely to buy that product
- clustering: are there natural groups of similar documents
- product recommendations: which products are similar to the customer’s past purchases
This is the first article of a set of articles describing the intuition, definition and use cases of cosine similarity in Big Data.
Documents are vectors, customer profiles are vectors
The first leap of imagination is to stop thinking of documents as text and of customer profiles as sets of clicks. Instead we model documents and customer profiles as vectors.
Definition
A vector, as it is defined in linear algebra, is a tuple of m numbers. In other words, the vector is a list where the elements are floating point numbers. The vector is of fixed size, which here will be denoted as m. m is the dimension of the vector.
In Python we can model vectors like this:
m = 1000 # dimension of vector vector = [0.0]**m #built a list of 1000 zeros vector[0] = 0.4 vector[1] = 0.82 ... vector[m - 1] = 0.001
One can also use the numpy vector class to work with vectors in Python.
From documents to vectors
Suppose that we look at the document:
"mary had a little lamb..."
Before we can proceed to transform this document into a vector, we need to know the vocabulary of the English language. This means that we need to know each word in the English language. The dimension of the vector representing a document will be equal to the number of words in the vocabulary. The number of words in the English language is large and it constantly grows. In practice one operates on a corpus of fixed number of documents. One pass over the corpus is required to establish the vocabulary.
#find the vocabulary of a document collection
document_collection = [
["once", "upon", "a", "time", "there", ...],
["mary", "had", "a", "little", "lamb", ...],
...
]
#a hash table that maps words to integer ids
word_to_id = {}
for document in document_collection:
for word in document:
if not word_to_id.has_key(word):
word_to_id[word] = word_to_id.size()
#print the vocabulary:
for (word, word_integer_id) in word_to_id:
print word, word_integer_id
Once you know the vocabulary, the vector representation of the document can be built:
document = ["mary", "had", "a", "little", "lamb", ...]
m = word_to_id.size()
vector = [0.0]**m #create a vector of dimension the vocabulary size
for word in document:
word_id = word_to_id[word]
vector[word_id] += 1
# vector[word_id] = count of word_id in document,
# if word does not appear the count is 0
Observations
The vector representation of documents loses word order
As it can be seen, the vector representation loses information about the ordering of the words. From the vector, we can read how many times each word occurs in the document. We cannot reconstruct the original sentence from the vector. However, for many tasks the “vector approximation” is sufficient to capture the meaning of the original document.
The vector contains mostly zeros.
When dealing with text documents the vocabulary can be of size of the order of 60000. Let us assume that the document contains 5 unique words. Then there are (60000 - 5) zeros. This means that representing vectors as lists in a computer program is not going to be efficient. This is easy to fix. We can use a hash table instead of a list, or a sparse vector instead of a dense vector.
The more serious problem is that if you take two randomly chosen documents from a collection, then most likely their overlap will be reported as empty. Partly the problem can be solved by converting the words to their root forms (a process known as stemming, e.g. job vs jobs), and collapsing synonyms (e.g. job vs. work) into the same word class. Not finding overlap when it should exist is a problem in machine learning known as “data sparsity” or the “curse of dimensionality”. There are special techniques to work around this problem but those will be discussed in a different blog post (UPCOMING).
Below is the code snippet that implements cosine similarity. At lines 5 and 6 documents 1 and 2 are converted to vectors. Both vectors have the same dimension. On line 10, we start looping over the elements of both vectors. We keep track of three counters: sum for the dot product, and two counters for the sum of squares of the elements of both vectors.
Comparing two documents
#assume we have access to the complete vocabulary
#in the word_to_id map
m = word_to_id.size()
document1 = ["mary", "had", ...]
document2 = [...]
vector1 = to_vector(document1, word_to_id) # line 5
vector2 = to_vector(document2, word_to_id) # line 6
sum = 0.0 # dot product
norm1 = 0.0 # the sum of squares of the components of vector1
norm2 = 0.0 # the sum of squares of the components of vector2
for i in range(0, m): #line 10
a = vector1[i]
b = vector2[i]
sum += a*b
norm1 += a*a
norm2 += b*b
#must guard against norm1 and norm2 being zero
#this means that at least one of the documents
#has no words
normalization = sqrt(norm1)*sqrt(norm2)
cosine_similarity = sum/normalization
Cosine Similarity is a way to measure overlap
Suppose that the vectors contain only zeros and ones. In this case vectors represent sets. The numberator is just a sum of 0’s and 1’s. We have a 1 only when both vectors have one in the same dimensions. Therefore, the numerator measures the number of dimensions on which both vectors agree.
The denominator is related to the size of the sets that each vector represents.
If one takes the view that cosine is a way to measure overlap, it is natural to compare the cosine to the dice coefficient and the Jaccard coefficient.
Customer profiles from click data
How does the above model apply to user profiles with click data? First, we can think of a user profile as a set of links (or pages) that the user clicked. We need to know the set of possible pages that the user can click to obtain the dimension of the vector.
user_profile = ["/index", "/socks", "/blouse", ...]
page_to_integer_id = a map describing the mapping of a page to an integer_id
m = #the number of all pages on the web site
vector = [0.0]**m #vector of length m
for page in user_profile:
page_id = page_to_integer_id[page]
vector[page_id] += 1
What does the normalization mean?
Mathematically the cosine similarity is expressed by the following formula:
Instead of writing the above formula, we can first normalize the vectors $a$ and $b$ by dividing by their length
After this normalization, cosine similarity is simply the dot product between the normalized vectors.
Geometric Interpretation
Geometrically the normalization means that the vectors lie on a unit sphere in an m-dimensional space. If we are working in two dimensions, this observation can be easily illustrated by drawing a circle of radius 1 and putting the end point of the vector on the circle as in the picture below. The origin of the vector is at the center of the cooridate system (0,0).
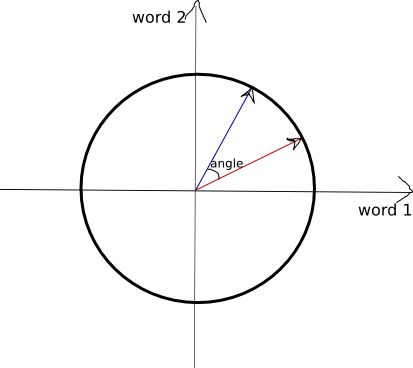
We can say that
similarity(a,b) = cosine of angle between the two vectors
Normalization is beneficial
Why is normalization important? Consider this question: how do you compare a short document to a long document. Normalization makes the documents comparable.
“Why normalization by vector length is good?” is a question that is much harder to answer. One can consider other ways of normalizing the vectors.
Cosine Similarity: Let’s actually make it work
I kept the current presentation up to the bare minimum in order to give a working understanding which is enough for software engineers to build simple applications. In the next blog post, I will discuss a few simple but important trick to working with cosine similarity: a set of data transformations that substantially improves the quality of the similarity matching.