Hierarchical Clustering With Random Projections: Part 1
In this and next blog posts, I will discuss some opportunities for data clustering using random projections.
Hierarchical Clustering
One of the simplest clustering approaches is bottom-up hierarchical clustering. In this approach one starts with each data point being its own “cluster”. If we start with $n$ data points we have $n$ clusters at the first iteration. Then the closest two clusters are merged and one ends up with $(n - 1)$ clusters. Continuing in this way, one obtains a tree. The original data points are at the leaves of the tree.
Index structure for nearest neighbor
Random projections are used to solve the nearest neighbor problem efficiently. This means that by using random projections one can construct an index which is able to efficiently execute a search operation. Given a point id, the closest point is returned as the answer to a search query.
One possibility to use this nearest-neighbor indexing structure is to find for each data point its closest point. Then we can use the so called single link clustering to merge the points. For example, if points (a,b) are neighbors and points (b, c) are neighbors, then we’ll put them together in the same cluster containing (a,b,c).
One can observe, that if for every point one finds the top nearest neighbor, and then applies single link clustering, then the size of the data set is reduced by at least a factor of two. Then one proceeds recursively until a predefined number of clusters if found. It takes less than $log(n)$ steps.
Kaggle Digits Dataset
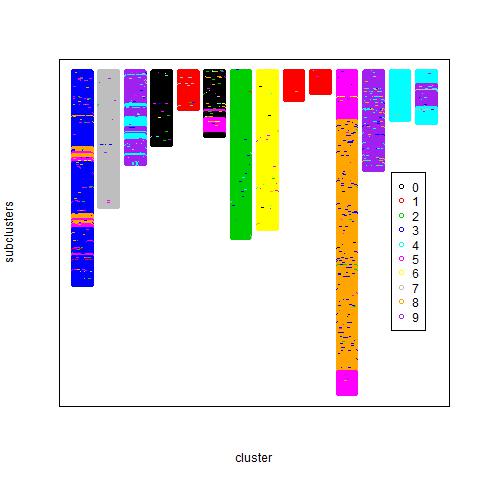
I am using the dataset for the Digit Recognizer Tutorial from Kaggle. This dataset has about 40000 images of digits from 0 to 9. I ran the clustering algorithm described above and set the algorithm to return less than 20 clusters. The clusters obtained are showed in the figure below. Each block represents a top-level cluster. The top-level clusters are composed of nested clusters which are represented as sub-blocks with different colors within each block. Each digit is represented as a data point in different color. If the digits had clustered perfectly, one would see 10 blocks each containing points of a single color.
Artificial Dataset
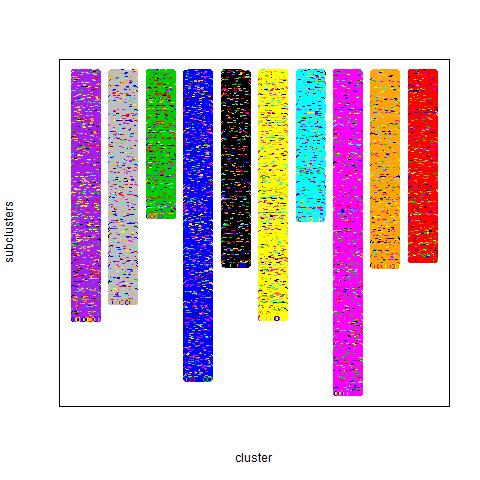
I ran the same algorithm on an artificial dataset. The dataset was generated in the following way. First ten prototype vectors of dimension 700 consisting of +1 and -1 were generated. Each +1/-1 was chosen with probability 0.5. Then 2000 datapoints were generated from each prototype by taking the prototype, selecting randomly 40% of the components and multiplying them by -1. This means that 40% of the prototype was corrupted by noise.
The result of the clustering is here:
Clustering Algorithm
The clustering algorithm is described in pseudo code below:
Input: a dataset of n points
Output: k clusters
def cluster(dataset, weights):
if dataset.numPoints < threshold:
return hierarchy of clusters
else:
index = buildRandomProjectionsIndex(dataset)
uf = unionFindStructure()
for each point a in dataset:
b = index.nearestNeighbor(a)
# compute b, the nearest neighbor of a
uf.merge(a,b)
clusters = uf.getConnectedComponents()
newDataset = create a new dataset of the next iteration
newWeights = []
for cluster in clusters:
clusterRepr = zero_vector
for point in cluster:
clusterRepr += weights(point)*datset.getVectorRepr(point)
length = compute the length of clusterRepr
newDataset.addVectorRepr(clusterRepr)
newWeights.add(length)
#call cluster recursively
cluster(newDataset, newWeights)
Remarks
As it can be seen, the digits dataset did not cluster perfectly. Some digit classes were merged in clusters with other digit classes. At this point, I believe, that this is due to representing each cluster by a single “average” vector. At the later stages of clustering, towards the root of the hierarchy, a cluster is likely to be a mixture of a number of prototypes.
In the next blog post, I will discuss a method that represents a cluster by the set of all points in the cluster, rather than a single representative vector.