A Language-Modeling Approach to Online Advertising
Introduction
I discuss a principled approach to matching users with online ads. The approach is based on a statistical technique known as the Language Modeling approach from the field of Information Retrieval.
The prerequisites for application of this method are quite standard. Namely a company should have access to:
- user browsing histories i.e. websites a user visited
- a database of advertisements annotated with keywords and other useful properties.
I do not assume that the advertising company has a large pool of users and any previously collected clicks. The approach here does not require training data and is not based on collaborative filtering. However, the company must have some idea about a user browsing profile in order to present meaningful ads.
The model
Assumption 1
I assume that browsing websites is a result of some knowledge need or interest. Even though this need (interest) is not directly observable, the user’s website visits which are a consequence of this need are observable. In the language of statistics, the user interest is a hidden random variable. This assumption is represented schematically below in the standard notation of graphical models:

For example, my interest in a hiking holiday in Austria is expressed by visiting a website about Zeller lake:

Assumption 2
The next assumption is that the ads that the company has in its ads database could also match the user browsing interests. That is the user might browse ads which match her interest. This assumption is expressed in the following model:

Under this assumption, an ad about visiting Klopeiner Lake in Carinthia national park in Austria might be relevant to my interest:

Putting assumption 1 and assumption 2 together we arrive at the following graphical model:
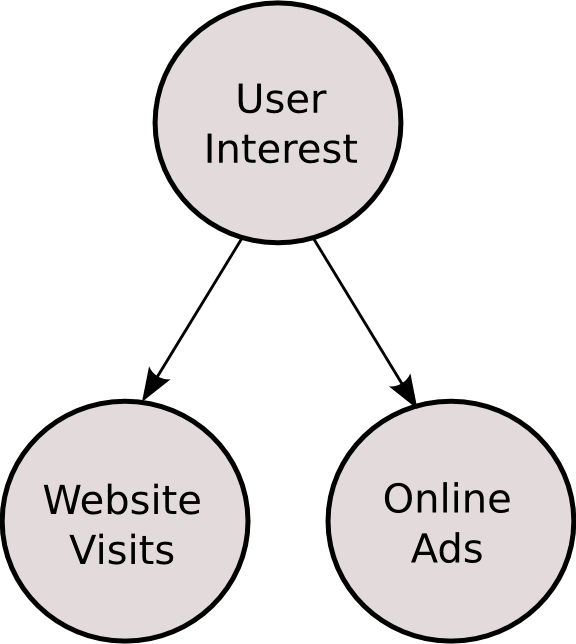
In terms of the examples above the combined model looks like:

The solution
Now that we have assumed the model of Figure 3, we can solve it.
Let us denote the following random variables
- I = User interest
- B = Browsing history or website visits
- A = Online ads
We seek to obtain P(A|I) = probability that the ad A is interesting for the user interest I. Currently we assume this is the same as the probability that the user clicks on the ad.
We can display the ads with the highest P(A|I) or with highest Cost(P(A|I), …) where Cost is some function which also includes monetization information from the advertiser in addition to the probability of user click.
Next we assume that we will represent the variables I, W and A as multinomial distribution over word counts. This is standard practice in infomation retrieval. We will write this assumption as:
- I ~ (w1, w2, …, wN)
- B ~ (w1, w2, …, wN)
- A ~ (w1, w2, …, wN)
The next steps are to estimate:
- P(I|B)
- P(A|I)
We can use standard methods for distribution estimation from the Language Modeling approach to Information Retrieval. These methods include components that take into account the informativeness (specificity, rarity) of words and probability smoothing methods.
On the estimation of P(I|B) one could use standard methods that include the following components.
- Augment (smooth) the word distribution of the browsing history by pages linked to or linking from a particular page
- Augment (smooth) the word distribution for a particular user through browsing distributions of other users
- Augment (smooth) the word distribution using the technique of the translation model in Information Retrieval
- Clustering of visited pages and estimation within a cluster group.
- Instead of using one multinomial distribution for the user history, use a set of distributions.
- Temporal aspect. Use only the most recent browsing history.
The purpose of these techniques is to improve the estimation of the probability p(word|B) and the representation of the browsing history.
The result from the step $P(I \vert B)$ is a distribution with probabilities $i_1 = p(w_1)$, $i_2 = p(w_2)$, …, $i_N = p(w_N)$. As mentioned above we could also use a set of those properly weighted.
The simplest implementation of $P(A \vert I)$ is to use the sum of the logs of those $i_1, i_2,\ldots$ that correspond to words that appear in the ad. In a more complex implementation the words will be weighted based on counts in the ad. We could also consider a method where we know the distribution of $P(A)$. This distribution depends on the content of the ad and the website of the ad sponsor. We could go to the sponsor website and automatically fetch its content through which we infer the distribution. If this distribution is $a_1=p(w_1), a_2 = p(w_2), \ldots, a_N = p(w_N)$, then the scoring of the ad for the user will be $\sum_{i=1}^N a_i \ln(i_1)$
Alternative scoring methods
Under the same model in Figure 3 we could posit two alternative scoring methods.
Alternative method 1. Here instead of P(A|I) we treat P(A) and P(B) as count vectors or samples. We ask if those two samples come from the same distribution I. The test whether the ad and the browsing history come from the same distribution is the Jenson-Shannon divergence.
Alternative method 2. Instead of modeling P(A|I) we can introduce a new variable R for relevance and NR for non-relevance. So for a particular ad, we ask whether the ad is relevant. This is what is the odds P(R|A,I)/P(NR|A,I). Such motivation is available in the origins of the OkapiBM25 model. Since in the OkapiBM25 model the query is very short compared to browsing history its usage is in that case sub-optimal. It is better to use OkapiBM25 extensions for probabilistic relevance feedback. See for example 9.1.2 in Introduction to Information Retrieval by Manning, Raghavan and Schütze
Differences from standard implementations in Lucene (ElasticSearch, Solr)
It might seem that the methods described are already available in Lucene (ElasticSearch, Solr) implementations. However, the formula that I described here differs from the Lucene formula. The Lucene formulas typically measure P(Q|D), while in the proposed model I suggest P(D|Q) where D (the document) is the ad, and Q (the query) is the user information. A second difference is related to the query length. In standard search, the query is just a few words. The methods in Lucene are optimized for this case. In the case of advertising the query is the available user information. In the presented model, this information is a set of probability distributions. The distribution has many components, but the most useful ones are a hundred words with counts.