Singular Value Decomposition: All Posts
Singular Value Decomposition (SVD)
This series contains tips and tricks about the SVD. SVD is a foundational technique in Machine Learning. This series approaches the SVD from a few view points to build more useful intuition what is actually happening behind the equations.
The equation behind SVD is a very elegant mathematical statement, but also a very “thick” one as well.
The SVD of a matrix is defined as
In data problems, $X$ is typically the dataset, and the SVD helps create a more “condensed” representation. Although a simple statement to state, it is not so simple to understand what this statement gives us.
As a data scientist, I prefer much more the following way to write the SVD:
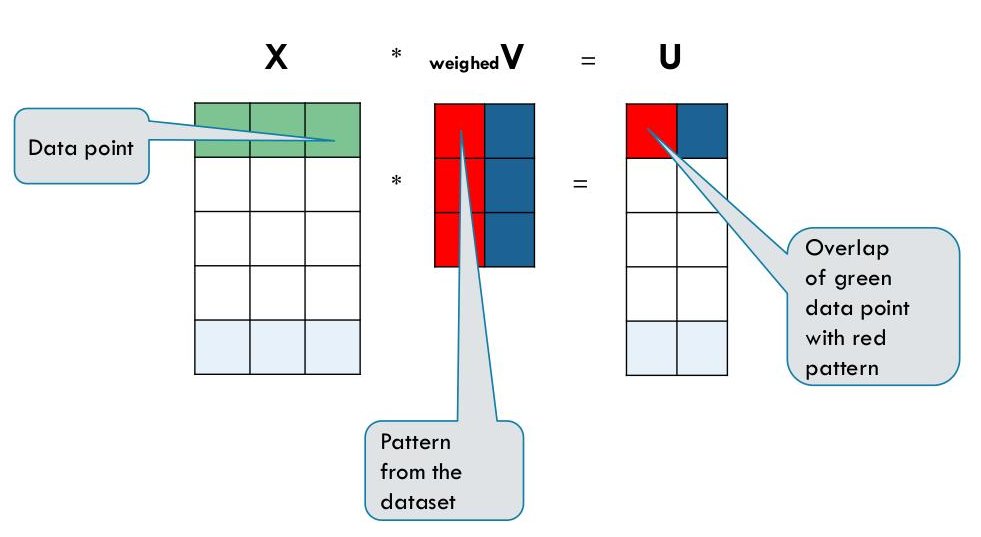
This way to write the SVD gives as the interpetation that SVD extract patterns from the data represented by columns of the matrix V. This is the red and green column in the picture. Then each data point is compared with the patterns via the dot product. The dot product is a way to measure overlap. In the end, the matrix U gives us a new representation of the data based on the patterns discovered in the original dataset.
SVD is used in Search, Recommendation Systems and Natural Language Processing. In those fields the application of SVD is known under the names of Latent Semantic Indexing or Latent Semantic Analysis.
- The Swiss Army Knife of Big Data
- Latent Semantic Indexing: A bit of history
- Worked out equations for improving Euclidean Distance with the SVD
- SVD: Selected References
Check out the sidebar for more topics.